The JumpeR R package is used for converting human readable track and field (athletics) results into data frames for use in analysis.
JumpeR is available on CRAN install.packages(JumpeR)
devtools::install_github("gpilgrim2670/JumpeR")
v0.3.0 - November 16th, 2021
Package is still under heavy development so development versions will be unstable. Please use the stable CRAN release unless you have a very good reason not to.
JumpeR reads track and field results into R, similar to what the SwimmeR package does for swimming results.
JumpeR currently supports reading in single column Hy-tek/Active.com style results in either .html or .pdf format. JumpeR also supports Flash Results style results in .pdf format (but not html).
These are Hy-tek results in html format, from the 2019 Greg Page relays at Cornell University. This particular file contains the entire meet.

It can be imported into R using JumpeR:

This is a Hy-tek .pdf results file, from the Singapore Masters Track and Field Association 2019 Championship. It contains the entire meet.

Once saved (it’s included in JumpeR as an example) it can be imported into R using JumpeR:
tf_parse(
read_results(
system.file("extdata", "SMTFA-2019-Full-Results.pdf", package = "JumpeR")
),
rounds = TRUE
)
This is a Flash Results .pdf result, from the prelims of the 2019 NCAA Men’s 100m Championships.

It can be imported into R using JumpeR:
tf_parse(
read_results(
"https://www.flashresults.com/2019_Meets/Outdoor/06-05_NCAAOTF-Austin/001-1.pdf"
)
)
Flash Results also post .html version of results like these, which are currently NOT supported.

JumpeR reads track and field results into R and outputs tidy dataframes. JumpeR uses read_results to read in either a PDF or HTML file (like a url) and the tf_parse (for track and field) function to convert the read file to a tidy dataframe.
read_results has two arguments. * file, which is the file path to read in * node, required only for HTML files, this is a CSS selector node where the results reside. node defaults to "pre", which has been correct in every instance tested thus far.
tf_parse has six arguments as of version 0.1.0.
file is the output of read_results and is required.
avoid is a list of strings. Rows in file containing any of those strings will not be included in the final results. avoid is optional. Incorrectly specifying it may lead to nonsense rows in the final data frame, but will not cause an error. Nonsense rows can be removed after import.
typo and replacement work together to fix typos, by replacing them with replacements. Strings in typo will be replaced by strings in replacement in element index order - that is the first element of typo will be replaced everywhere it appears by the first element of replacement. Uncorrected typos can cause lost data and nonsense rows.
relay_athletes defaults to FALSE. Setting it to TRUE will cause tf_parse to try to pull out the names of athletes participating in relays. Athlete names will be in separate columns called Relay_Athlete_1, Relay_Athlete_2 etc. etc.
Here’s the Women’s 4x400m relay from the 2019 Greg Page relays at Cornell University.

Here’s the same thing after importing with JumpeR
tf_parse(
read_results(
"https://www.leonetiming.com/2019/Indoor/GregPageRelays/Results.htm"
),
relay_athletes = TRUE
)
rounds records a unit of length for events where athletes get to try multiple times (long jump, javelin, pole vault etc. - basically the “field” events in track and field). The default is FALSE but setting rounds to TRUE will cause tf_parse to attempt to collect the distance/height (or FOUL) for each round. New columns called Round_1, Round_2 etc. will be created.Here’s the long jump prelims from the 2019 Virginia Grand Prix at the University of Virginia with the “rounds” highlighted in yellow.
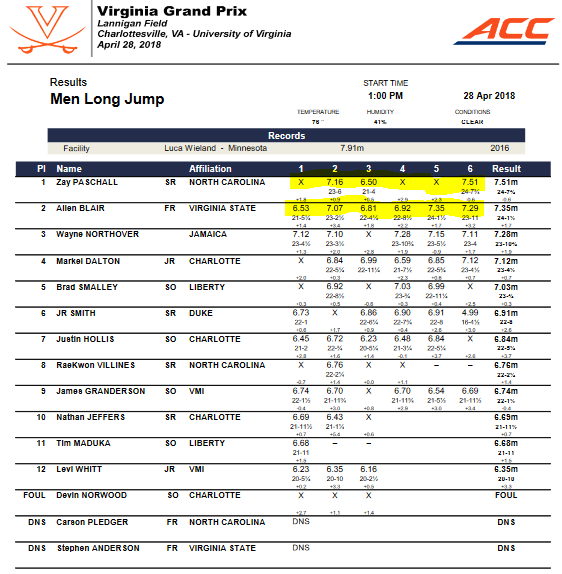
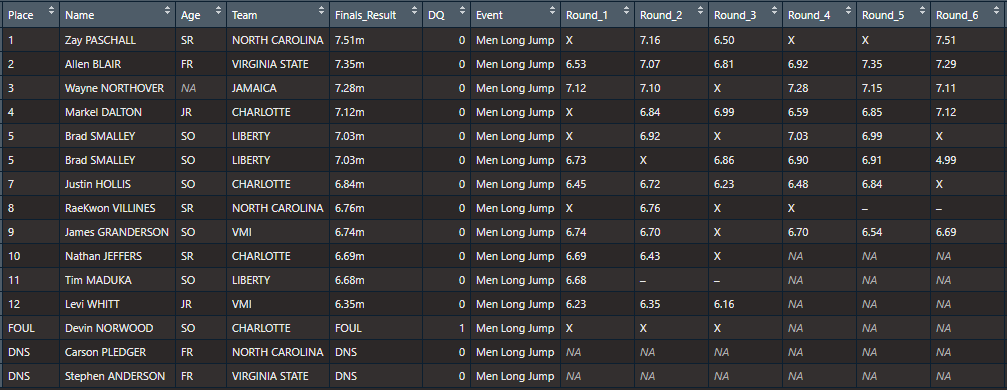
Here’s the same thing after importing with JumpeR
tf_parse(
read_results(
"https://www.flashresults.com/2018_Meets/Outdoor/04-28_VirginiaGrandPrix/035-1.pdf"
),
rounds = TRUE
)
round_attempts records the outcome of each attempt (height) in the vertical jumping events (high jump, pole vault). The default for round_attempts is FALSE but setting it to TRUE will include these values (usually some combination of “X”, “O” and “-”) in new columns called Round_1_Attempts, Round_2_Attempts etc. If round_attempts = TRUE then rounds = TRUE must be set as well.Here’s the pole vault results from the 2019 Duke Invite at (natch) Duke University with the “round_attempts” highlighted in yellow and the “rounds” circled in red.
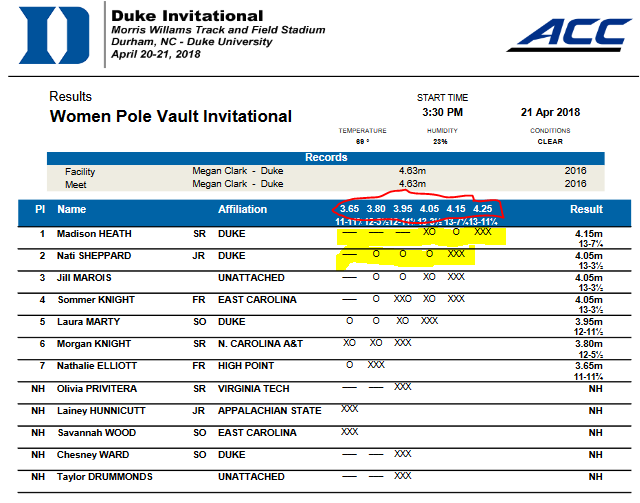
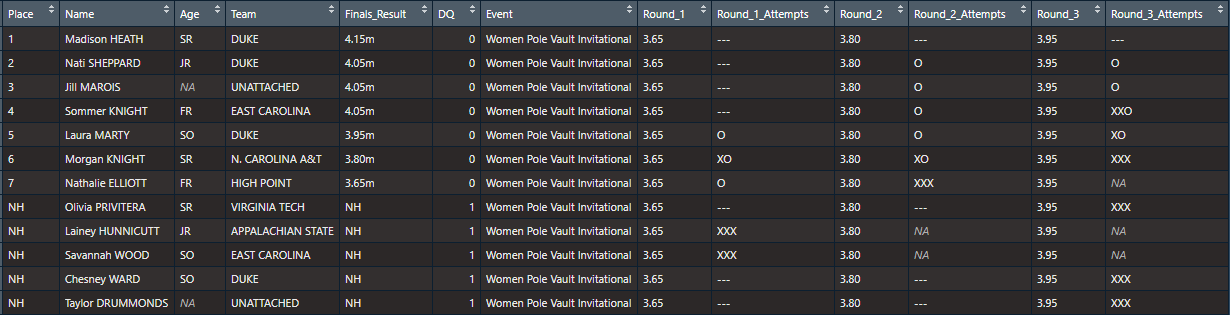
Here’s the same thing after importing with JumpeR - adding all these columns makes the results very wide.
tf_parse(
read_results(
"https://www.flashresults.com/2018_Meets/Outdoor/04-20_DukeInvite/014-1.pdf"
),
rounds = TRUE,
round_attempts = TRUE
)
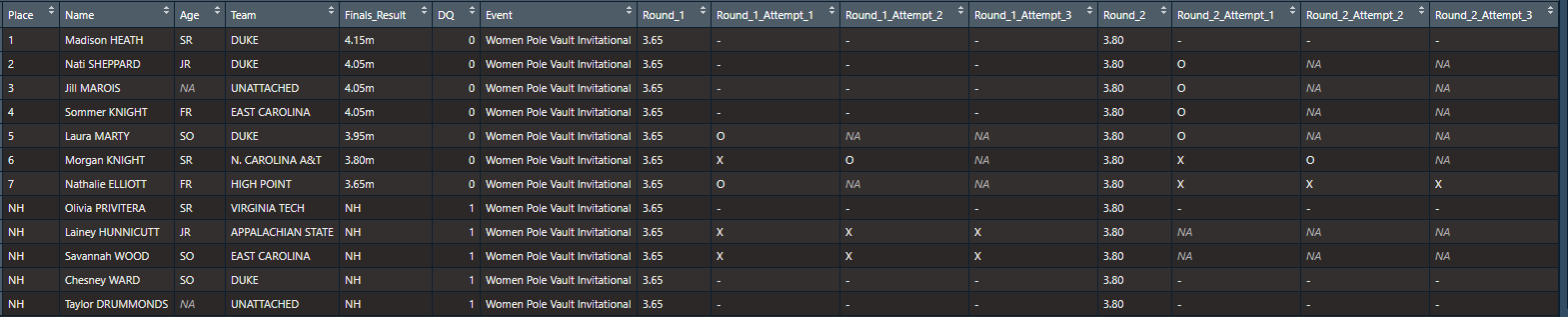
split_attempts setting split_attempts = TRUE will cause tf_parse to break each Round_X_Attempts column into pieces. A column containing “XXO” for example will become three columns, one containing “X”, the second containing the second “X” and the third containing “O”. This will mean there are a lot of columns! If split_attempts = TRUE then round_attempts must be TRUE as well.Looking at those same Duke pole vault results, here’s how using split_attempts works - adding all these columns make the results extremely wide. I’m only going to show the first six split columns, called Round_1_Attempt_1, Round_1_Attempt_2, Round_1_Attempt_3 etc..
tf_parse(
read_results(
"https://www.flashresults.com/2018_Meets/Outdoor/04-20_DukeInvite/014-1.pdf"
),
rounds = TRUE,
round_attempts = TRUE,
split_attempts = TRUE
)
See ?tf_parse for more information.
While setting split_attempts = TRUE in tf_parse can be used to generate wide format results of vertical jump attempts it might be more useful to create long format results instead. This can be accomplished after tf_parse.
Using those same Duke pole vault results here’s the first place finisher in long format
df <-
tf_parse(
read_results(
"https://www.flashresults.com/2018_Meets/Outdoor/04-20_DukeInvite/014-1.pdf"
),
rounds = TRUE,
round_attempts = TRUE,
)
df %>%
attempts_split_long() %>%
select(Place, Name, Age, Team, Finals_Result, Event, Bar_Height, Attempt, Result)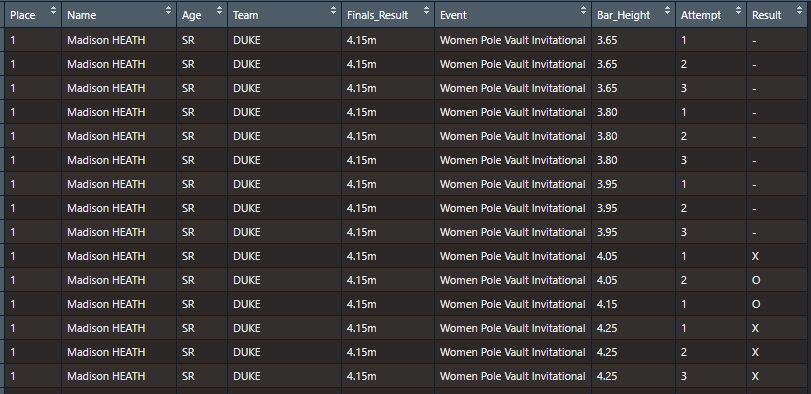
By default all results (like the Finals_Result column) returned by JumpeR are characters, not numeric. This is because lots of results don’t fit Rs notions of what a number is. A result like "1.65m" for a long jump can’t be a number because of the “m”. A result like "1:45.32" as a time can’t be a number because of the “:”. Luckily JumpeR is here to help with all of that. Passing results to math_format will return results formatted as numeric, such that they can be used in math.
Please note however that JumpeR doesn’t understand units. Passing
will return 1.65 (meters, but not noted), NA (nice touch there), and 105.32 (seconds, also not noted). You’ll need to keep track of your units yourself, or perhaps use the units package. This is an area of possible future development.
The best use of math_format is to convert an entire column, like Finals_Results
df <- tf_parse(
read_results(
"https://www.leonetiming.com/2019/Indoor/GregPageRelays/Results.htm"
)
)
library(dplyr)
df <- df %>%
mutate(Finals_Result_Math = math_format(Finals_Result)) %>%
select(Place, Name, Team, Finals_Result, Finals_Result_Math, Event)You’re welcome to contact me with bug reports, feature requests, etc. for JumpeR.
If you find bug, please provide a minimal reproducible example at github.
JumpeR is conceptually very similar to the SwimmeR package, which I also developed and maintain. I do a lot of demos on how to use SwimmeR at my blog Swimming + Data Science, which may be instructive for users of JumpeR as well. SwimmeR also has a vignette (JumpeR does not at the moment).