

![]()
adjclust is a package that provides methods to perform
adjacency-constrained hierarchical agglomerative clustering.
Adjacency-constrained hierarchical agglomerative clustering is
hierarchical agglomerative clustering (HAC) in which each observation is
associated to a position, and the clustering is constrained so as only
adjacent clusters are merged. It is useful in bioinformatics
(e.g. Genome Wide Association Studies or Hi-C data analysis).
adjclust provides three user level functions:
adjClust, snpClust and hicClust,
which are briefly explained below.
You can install adjclust from github with:
# install.packages("devtools")
devtools::install_github("pneuvial/adjclust")adjClustadjClust performs adjacency-constrained HAC for standard
and sparse, similarity and dissimilarity matrices and dist
objects. Matrix::dgCMatrix and
Matrix::dsCMatrix are the supported sparse matrix classes.
Let’s look at a basic example
library("adjclust")
sim <- matrix(c(1.0, 0.5, 0.2, 0.1,
0.5, 1.0, 0.1, 0.2,
0.2, 0.1, 1.0, 0.6,
0.1, 0.2 ,0.6 ,1.0), nrow=4)
h <- 3
fit <- adjClust(sim, "similarity", h)
plot(fit)
The result is of class chac. It can be plotted as a
dendrogram (as shown above). Successive merge and heights of clustering
can be obtained by fit$merge and fit$height
respectively.
snpClustsnpClust performs adjacency-constrained HAC for specific
application of Genome Wide Association Studies (GWAS). A minimal example
is given below. See GWAS Vignette
for details.
library("snpStats")
#> Loading required package: survival
#> Loading required package: Matrix
data("ld.example", package = "snpStats")
geno <- ceph.1mb[, -316] ## drop one SNP leading to one missing LD value
h <- 100
ld.ceph <- ld(geno, stats = "R.squared", depth = h)
image(ld.ceph, lwd = 0)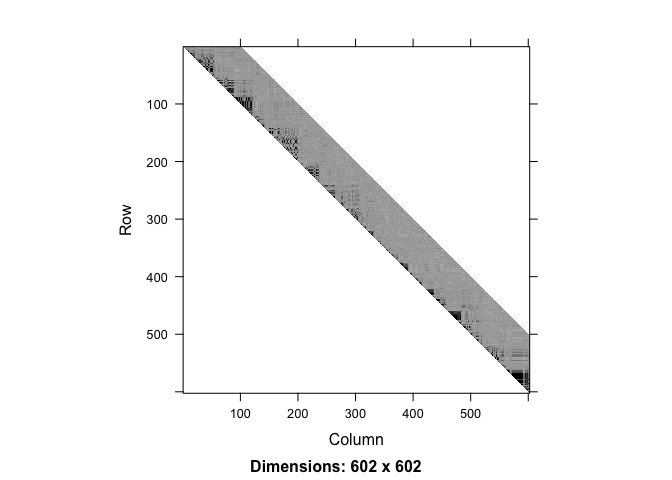
fit <- snpClust(geno, stats = "R.squared", h = h)
#> Warning in run.snpClust(x, h = h, stats = stats): Forcing the LD similarity to
#> be smaller than or equal to 1
#> Note: 133 merges with non increasing heights.
plot(fit)
#> Warning in plot.chac(fit):
#> Detected reversals in dendrogram: mode = 'corrected', 'within-disp' or 'total-disp' might be more relevant.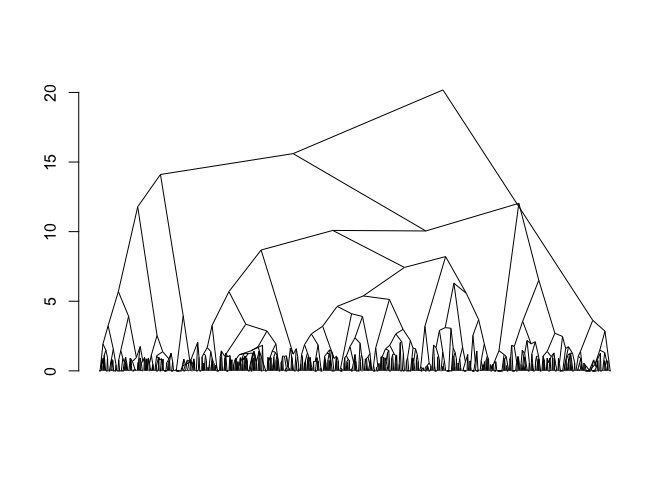
sel_clust <- select(fit, "bs")
plotSim(as.matrix(ld.ceph), clustering = sel_clust, dendro = fit)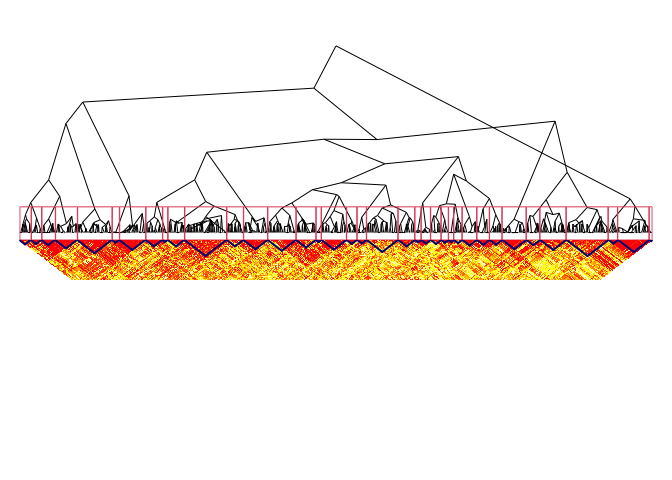
hicClusthicClust performs adjacency-constrained HAC for specific
application of Hi-C data analysis. A minimal example is given below. See
Hi-C Vignette for details.
library("HiTC")
#> Warning: package 'BiocGenerics' was built under R version 4.0.5
#> Warning: package 'GenomeInfoDb' was built under R version 4.0.5load(system.file("extdata", "hic_imr90_40_XX.rda", package = "adjclust"))
binned <- binningC(hic_imr90_40_XX, binsize = 5e5)
#> Bin size 'xgi' =500488 [1x500488]
#> Bin size 'ygi' =500488 [1x500488]
mapC(binned)
#> minrange= 104 - maxrange= 36776.8
fitB <- hicClust(binned)
#> Note: 5 merges with non increasing heights.
plot(fitB)
#> Warning in plot.chac(fitB):
#> Detected reversals in dendrogram: mode = 'corrected', 'within-disp' or 'total-disp' might be more relevant.
plotSim(intdata(binned), dendro = fitB) # default: log scale for colors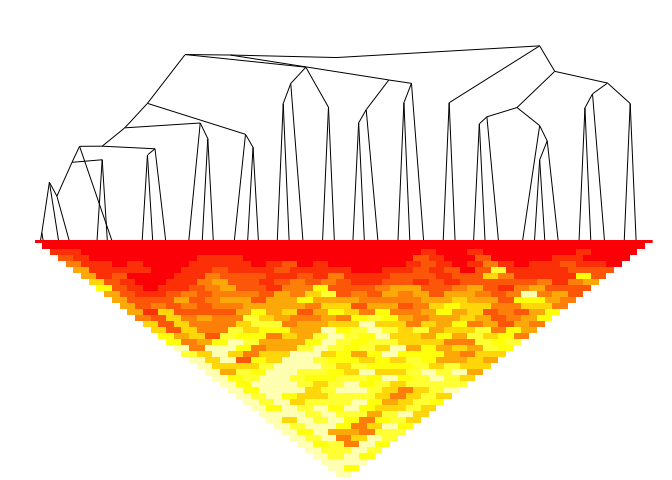
Version 0.4.0 of this package was completed by Shubham Chaturvedi as a part of the Google Summer of Code 2017 program.