![]()
![]()

![]()

An easy way to examine archaeological count data. tabula provides several tests and measures of diversity: heterogeneity and evenness (Brillouin, Shannon, Simpson, etc.), richness and rarefaction (Chao1, Chao2, ACE, ICE, etc.), turnover and similarity (Brainerd-Robinson, etc.). The package make it easy to visualize count data and statistical thresholds: rank vs. abundance plots, heatmaps, Ford (1962) and Bertin (1977) diagrams.
kairos is a companion package to tabula that provides functions for chronological modeling and dating of archaeological assemblages from count data.
To cite tabula in publications use:
Frerebeau, Nicolas (2019). tabula: An R Package for Analysis,
Seriation, and Visualization of Archaeological Count Data. Journal of
Open Source Software, 4(44), 1821. DOI 10.21105/joss.01821.
Une entrée BibTeX pour les utilisateurs LaTeX est
@Article{,
title = {{tabula}: An R Package for Analysis, Seriation, and Visualization of Archaeological Count Data},
author = {Nicolas Frerebeau},
year = {2019},
journal = {Journal of Open Source Software},
volume = {4},
number = {44},
page = {1821},
doi = {10.21105/joss.01821},
}You can install the released version of tabula from CRAN with:
install.packages("tabula")And the development version from GitHub with:
# install.packages("remotes")
remotes::install_github("tesselle/tabula")## Load packages
library(folio) # Datasets
library(khroma) # Color scales
library(ggplot2)
library(tabula)It assumes that you keep your data tidy: each variable (type/taxa) must be saved in its own column and each observation (sample/case) must be saved in its own row.
Several types of graphs are available in tabula which uses ggplot2 for plotting informations. This makes it easy to customize diagrams (e.g. using themes and scales).
Bertin or Ford (battleship curve) diagrams can be plotted, with statistic threshold (including B. Desachy’s sériographe).
## Bertin matrix with variables scaled to 0-1 and the variable mean as threshold
scale_01 <- function(x) (x - min(x)) / (max(x) - min(x))
plot_bertin(mississippi, threshold = mean, scale = scale_01) +
khroma::scale_fill_vibrant(name = "Mean")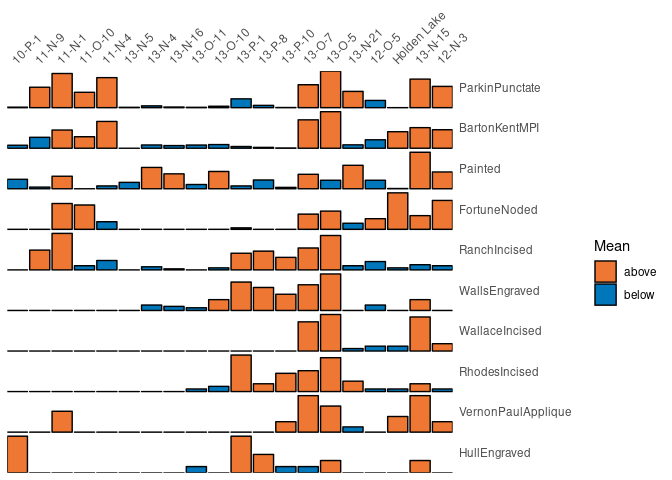
## Ford diagram
plot_ford(mississippi)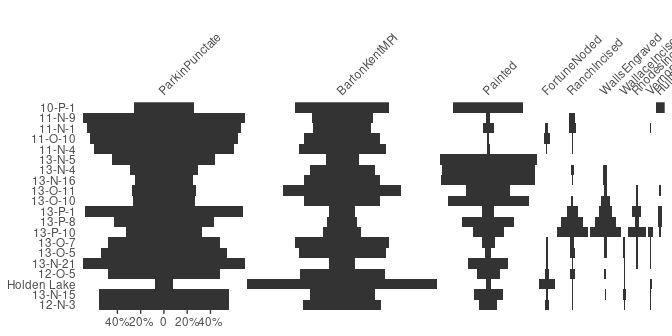
Spot matrix1 allows direct examination of data:
## Plot co-occurrence of types
## (i.e. how many times (percent) each pairs of taxa occur together
## in at least one sample.)
plot_spot(mississippi, freq = TRUE) +
ggplot2::labs(size = "Co-occurrence", colour = "Co-occurrence") +
khroma::scale_colour_YlOrBr()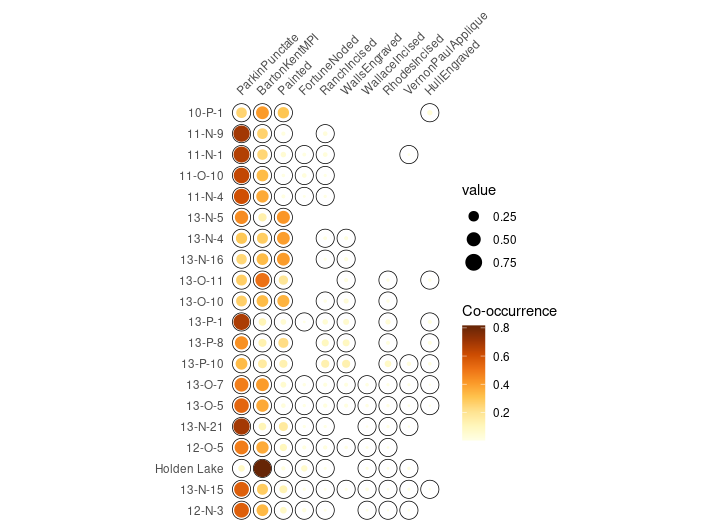
Diversity can be measured according to several indices
(referred to as indices of heterogeneity – see
vignette("diversity")). Corresponding evenness
(i.e. a measure of how evenly individuals are distributed across the
sample) can also be computed, as well as richness and
rarefaction.
heterogeneity(mississippi, method = "shannon")
#> [1] 1.2027955 0.7646565 0.9293974 0.8228576 0.7901428 0.9998430 1.2051989
#> [8] 1.1776226 1.1533432 1.2884172 1.1725355 1.5296294 1.7952443 1.1627477
#> [15] 1.0718463 0.9205717 1.1751002 0.7307620 1.1270126 1.0270291Measure diversity by comparing to simulated assemblages:
set.seed(12345)
## Data from Conkey 1980, Kintigh 1989, p. 28
chevelon |>
heterogeneity(method = "shannon") |>
simulate() |>
plot()
chevelon |>
richness(method = "count") |>
simulate() |>
plot()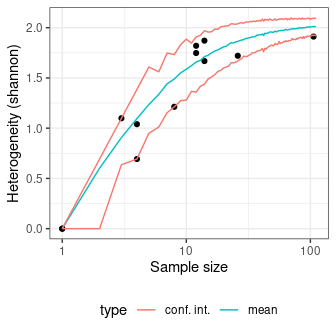
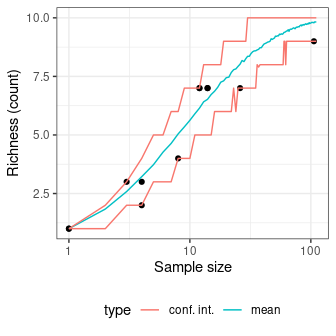
Several methods can be used to ascertain the degree of turnover in taxa composition along a gradient on qualitative (presence/absence) data. It assumes that the order of the matrix rows (from 1 to n) follows the progression along the gradient/transect.
Diversity can also be measured by addressing similarity between pairs of sites:
## Calculate the Brainerd-Robinson index
## Plot the similarity matrix
s <- similarity(mississippi, method = "brainerd")
plot_spot(s) +
khroma::scale_colour_iridescent(name = "brainerd")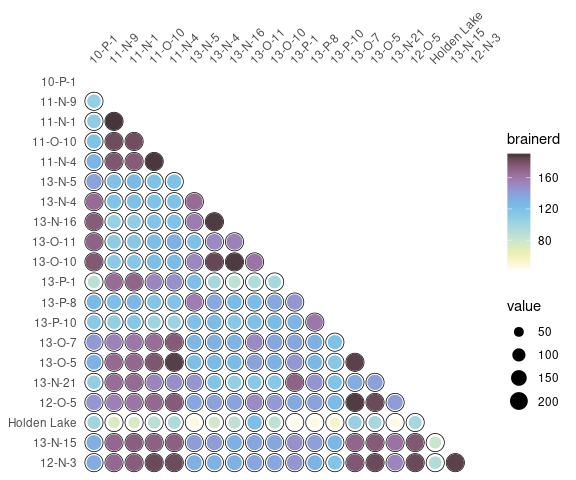
Please note that the tabula project is released with a Contributor Code of Conduct. By contributing to this project, you agree to abide by its terms.